I förra inlägget visade jag hur man laddar hem data från SCB med json som returformat. Ett alternativ är att istället ladda hem data som csv. Vinsten med det är att jag får med namn i klartext och inte bara koder. För regioner får jag alltså med kommunnamnen och inte bara kommunkod. Nackdelen är att det blir lite besvärligare att få en bra tabellstruktur.
Den här gången har jag valt plocka värden ur alla dimensioner i SCB:s befolkningstabell i det grafiska webbgränssnittet för SCB:s databas.
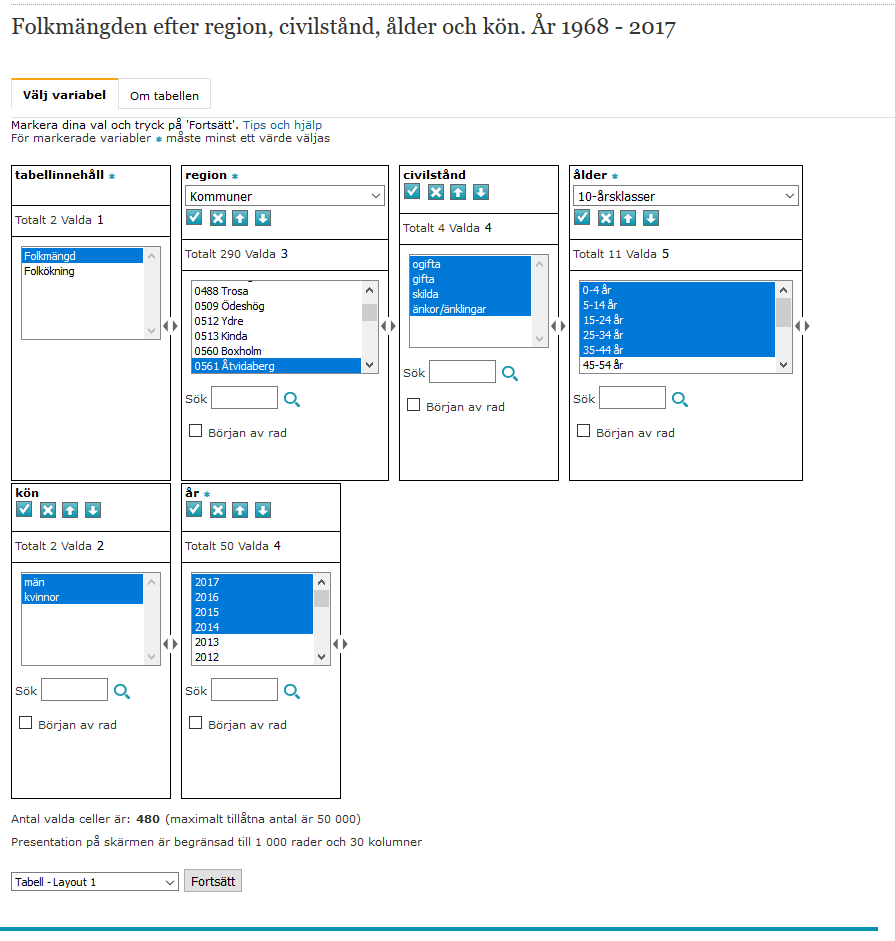
Jag har sedan valt att visa resultatet som “tabell . layout 1”, och sedan valt att visa json-frågan på resultatsidan.
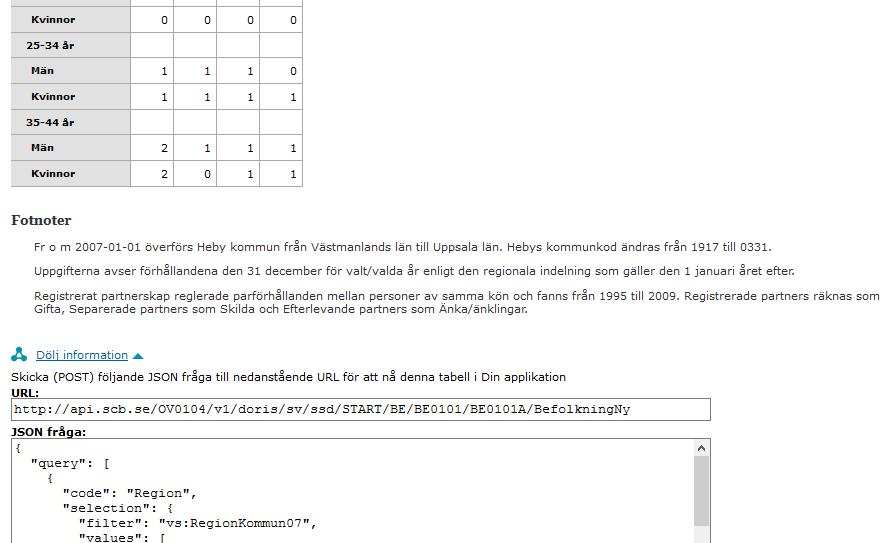
I koden nedan har jag klistrat in json-koden för frågan till apiet och sparat den i variablen “bodytext” och jag har sparat URL:en till api:et i variabeln “apiurl”. Notera att jag denna gång har valt “csv” som format under “response”.
library(jsonlite)
library(httr)
library(tidyr)
library(dplyr)
library(stringr)
library(janitor)
apiurl <-
"http://api.scb.se/OV0104/v1/doris/sv/ssd/BE/BE0101/BE0101A/BefolkningNy"
bodytxt0 <- '{
"query": [
{
"code": "Region",
"selection": {
"filter": "vs:RegionKommun07",
"values": [
"0561",
"0562",
"0563"
]
}
},
{
"code": "Civilstand",
"selection": {
"filter": "item",
"values": [
"OG",
"G",
"SK",
"ÄNKL"
]
}
},
{
"code": "Alder",
"selection": {
"filter": "agg:Ålder10år",
"values": [
"-4",
"5-14",
"15-24",
"25-34",
"35-44"
]
}
},
{
"code": "Kon",
"selection": {
"filter": "item",
"values": [
"1",
"2"
]
}
},
{
"code": "ContentsCode",
"selection": {
"filter": "item",
"values": [
"BE0101N1"
]
}
},
{
"code": "Tid",
"selection": {
"filter": "item",
"values": [
"2014",
"2015",
"2016",
"2017"
]
}
}
],
"response": {
"format": "csv"
}
}'I nästa steg laddar jag hem data och sparar i dataframen df:
bodytxt <- jsonlite::fromJSON(bodytxt0,
simplifyVector = FALSE,
simplifyDataFrame = FALSE)
req <- POST(apiurl,
body = bodytxt, encode = "json", verbose()) stop_for_status(req)
df <- content(req)Nu har jag data sparat i en dataframe, men dataframen har en massa konstiga attribut som jag vill bli av med. Eftersom kolumnnamnen försvinner när jag raderar attributen, så sparar jag ner kolumnnamen i variablen “namn” innan jag raderar attributen genom att sätta “attributes(df) <- NULL”. Att radera attributen gör också att dataframen görs om till en list. Jag återställer därefter kolumnnamnen och återskapar en dataframe med as_tibble(df).
Eftersom kolumnnamnen från SCB kan innehålla flera ord och svenska tecken, så använder jag mig av paketet janitor, vilket har en funktion som heter clean_names, vilket skapar variabelnamn som följer R:s standard.
namn <- names(df)
attributes(df) <- NULL
names(df) <- namn
df <- as_tibble(df)
df <- janitor::clean_names(df)
head(df)## # A tibble: 6 x 8
## region civilstand alder kon folkmangd_2014 folkmangd_2015 folkmangd_2016
## <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl>
## 1 0561 ~ ogifta 0-4 ~ män 273 297 306
## 2 0561 ~ ogifta 0-4 ~ kvin~ 275 293 318
## 3 0561 ~ ogifta 5-14~ män 618 618 627
## 4 0561 ~ ogifta 5-14~ kvin~ 641 629 627
## 5 0561 ~ ogifta 15-2~ män 696 689 653
## 6 0561 ~ ogifta 15-2~ kvin~ 635 626 619
## # ... with 1 more variable: folkmangd_2017 <dbl>Resultatet ser ganska ok ut, men befolkningen för varje årtal ligger i en egen kolumn. Jag vill helst att alla årtal ska ligga i en egen kolumn. Paketet tidyr har en funktion som heter “gather” som kan användas för att omformatera tabellen som jag vill ha den. Jag använder även funktionern “str_remove_all” i stringr-paketet för att ta bort alla förekomster av “Folkmangd_” i aar- kolumnen, för att därefter ändra format från character till intiger. Jag vill dessutom att kommunkoderna och kommunnamnen ska stå i varsin kolumn. Detta gör jag med hjälp av “sepatate”-funktionen i tidyr.
df %>%
gather(aar, value, folkmangd_2014:folkmangd_2017) %>%
mutate(aar = str_remove_all(aar, "folkmangd_")) %>%
mutate(aar = as.integer(aar)) %>%
separate(
region,
c("kom_kod", "kom_namn"),
sep = " ",
extra = "merge",
remove = TRUE
)## # A tibble: 480 x 7
## kom_kod kom_namn civilstand alder kon aar value
## <chr> <chr> <chr> <chr> <chr> <int> <dbl>
## 1 0561 Åtvidaberg ogifta 0-4 år män 2014 273
## 2 0561 Åtvidaberg ogifta 0-4 år kvinnor 2014 275
## 3 0561 Åtvidaberg ogifta 5-14 år män 2014 618
## 4 0561 Åtvidaberg ogifta 5-14 år kvinnor 2014 641
## 5 0561 Åtvidaberg ogifta 15-24 år män 2014 696
## 6 0561 Åtvidaberg ogifta 15-24 år kvinnor 2014 635
## 7 0561 Åtvidaberg ogifta 25-34 år män 2014 397
## 8 0561 Åtvidaberg ogifta 25-34 år kvinnor 2014 277
## 9 0561 Åtvidaberg ogifta 35-44 år män 2014 320
## 10 0561 Åtvidaberg ogifta 35-44 år kvinnor 2014 227
## # ... with 470 more rowsNu ser tabellen ut om jag vill ha den!
Eftersom årtalen nästan alltid finns i den sista listan som ingår i variabeln “bodytext”, så går det att göra en mera generell lösning enligt nedan:
index <- length(bodytxt$query)
vardevar <- length(bodytxt[["query"]][[index]][["selection"]][["values"]]) - 1
df %>%
gather(aar, value, (ncol(.)-vardevar):ncol(.)) %>%
mutate(aar = str_remove_all(aar, "folkmangd_")) %>%
mutate(aar = as.integer(aar)) %>%
separate(
region,
c("kom_kod", "kom_namn"),
sep = " ",
extra = "merge",
remove = TRUE
)## # A tibble: 480 x 7
## kom_kod kom_namn civilstand alder kon aar value
## <chr> <chr> <chr> <chr> <chr> <int> <dbl>
## 1 0561 Åtvidaberg ogifta 0-4 år män 2014 273
## 2 0561 Åtvidaberg ogifta 0-4 år kvinnor 2014 275
## 3 0561 Åtvidaberg ogifta 5-14 år män 2014 618
## 4 0561 Åtvidaberg ogifta 5-14 år kvinnor 2014 641
## 5 0561 Åtvidaberg ogifta 15-24 år män 2014 696
## 6 0561 Åtvidaberg ogifta 15-24 år kvinnor 2014 635
## 7 0561 Åtvidaberg ogifta 25-34 år män 2014 397
## 8 0561 Åtvidaberg ogifta 25-34 år kvinnor 2014 277
## 9 0561 Åtvidaberg ogifta 35-44 år män 2014 320
## 10 0561 Åtvidaberg ogifta 35-44 år kvinnor 2014 227
## # ... with 470 more rows